Blob Storage in 9.2
With the introduction of 9.2 there are two new types of document stores:

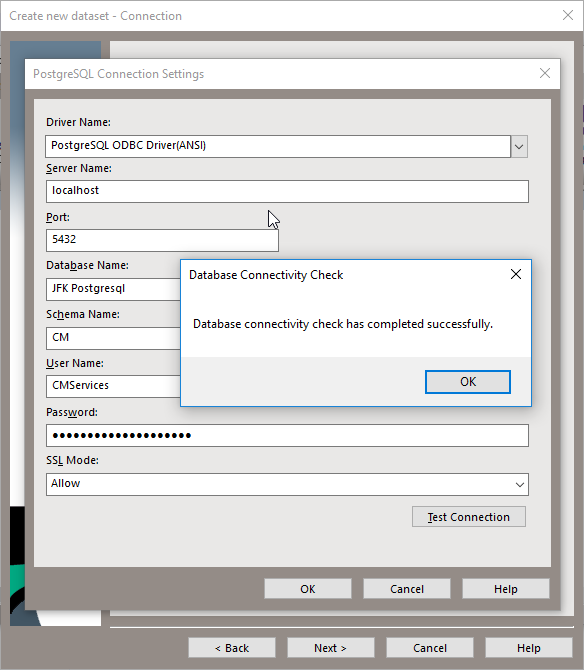
I'm going to focus on the Microsoft Azure Blob Store for now, as that's what I have access to. Before continuing within Content Manager, I first flip over to Azure and create a new storage container. Once that has been created I'll flip back over to CM.
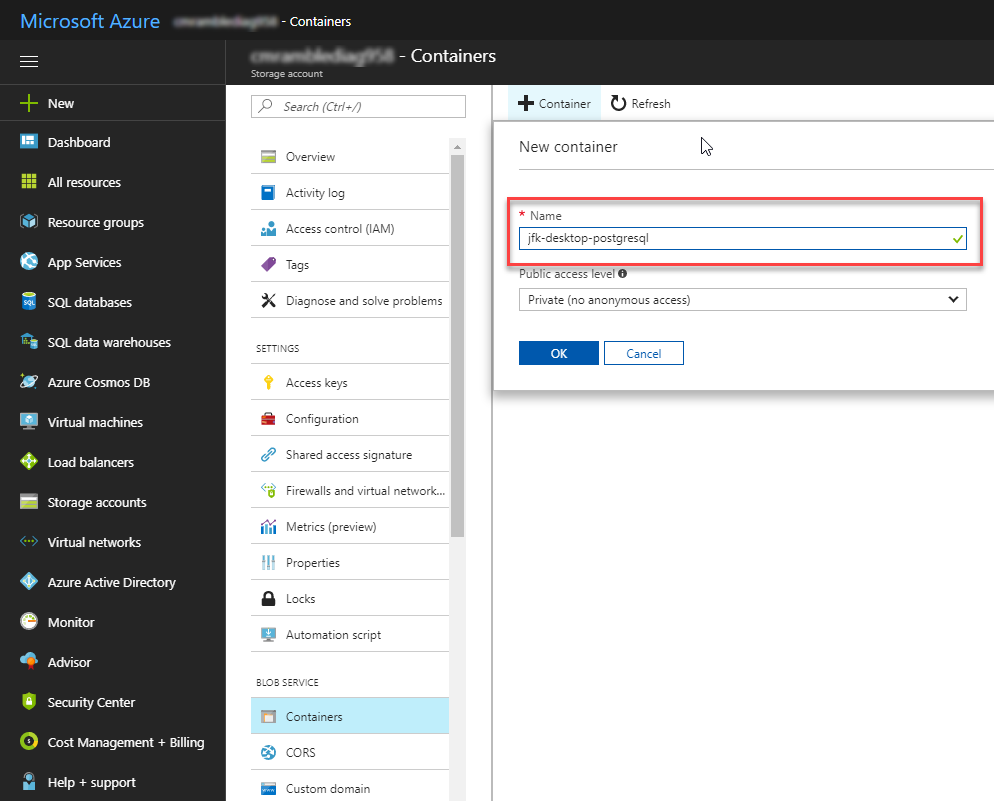
After creating the container I then went to the storage account and found the access keys. From there I can copy the connnection string to my clipboard and paste it into the new document store dialog.

Now back over in CM I can complete the details of the document store.

Then I clicked test to verify the settings...

Then I go create a new document record type that will use this document store...
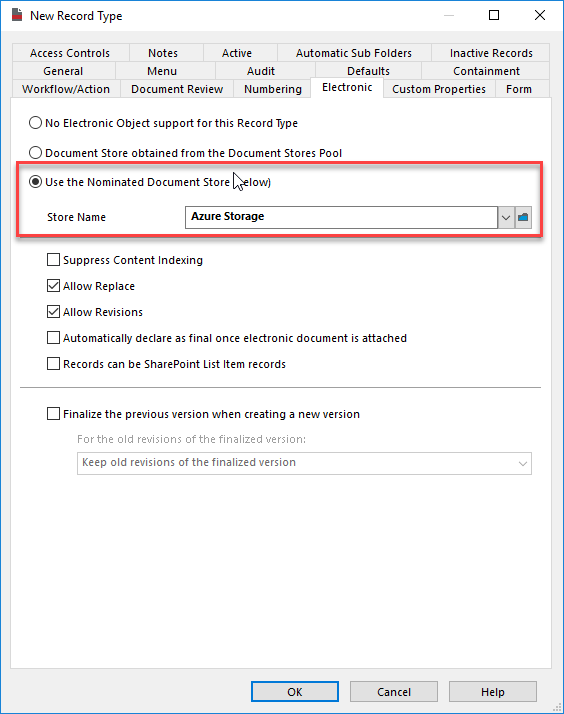
Now I can import a document and see what happens...

Over in Azure I can see the file has been uploaded..

I can manually transfer a few records to the document store from the electronic sub-menu of the context menu...
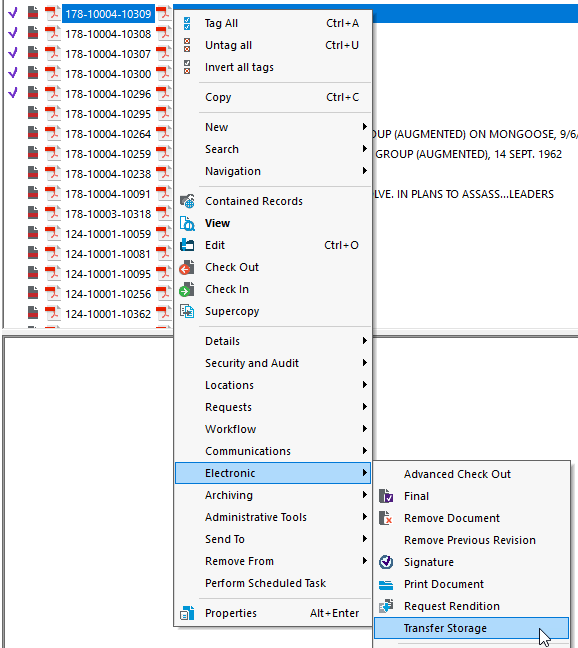
When prompted I just need to pick the new document store..

Alternatively, I could transfer the entire contents of any store into this one by selecting transfer from the context menu of a document store. The default options are the best. You should not need to use the others.

Lastly, I might want to use the Blob storage as a cheaper storage layer for older content. I should use the tiered storage options if available to me. I can make this a storage tier 3.

But I'll update the main document store so that the dates are tracked (it was already at level 1)...

Now I can create a saved search that I'll run routinely to move records to cheaper cloud storage. Note the search below finds all items using the main store but accessed more than a year ago.

I would tag all the resulting records and transfer them to storage tier 3. This could be automated via a powershell script as well. Lastly, workgroup server level document caching may be warranted when using blob storage.