Recreating the NARA JFK Assassination Archive within Content Manager
This past week the National Archives released numerous records from their JFK Assassination collection. As I reviewed what they've released I found myself trying to imagine how it might be managed within Content Manager (they are using OpenText). What sort of configuration would facilitate a declassification/review/release process? How would I handle new legislation and its' impact on my records retention? I hope to address these thoughts, and a few more, over the coming posts.
Before digging into those advanced topics, I'm going to try and import the released records into a new instance of Content Manager. I started by visiting the 2017 release page for the collection. The page shows me the meta-data for the records, a link to download each, and a link to download an excel spreadsheet (containing all the meta-data).

I downloaded the spreadsheet and then opened it to take a look at the columns. I should be able to map each field to a property within Content Manager, or decide to not import it at all. A few of the fields will need to have lookup sets created to support them.
Spreadsheet fields and my thoughts on mapping each:
- File Name -- URL of the electronic record, which will need to be retrieved and then attached to the CM record
- Record Num -- the NARA record number which will also be used as the CM record number
- NARA Release Date -- record date published
- Formerly Withheld -- create a new custom string property with supporting lookup set
- Agency -- create a new custom string property with supporting lookup set
- Doc Date -- record date created
- Doc Type -- create a new custom string property with supporting lookup set
- File Num -- this is interesting because values refer to container titles (not container record numbers), so initially I'll map it to a CM custom string property and later determine what to do with containers.
- To Name -- create a new custom string property
- From Name -- create a new custom string property
- Title -- record title
- Num Pages -- create a new custom number property
- Originator -- record owner
- Record Series -- if containers are used then this series would most likely be indicated on that container, so for now I'll import the values into a new custom string property and tackle it in a later post.
- Review Date -- create a new custom date property
- Comments -- here I'll create a new custom string property. Although I could use the existing record notes property, there are behavioral settings at the record type level which impact user's abilities to interact with that field and therefore shouldn't be used relied upon (I don't think so at least).
- Pages Released -- create a new custom number property
With the mapping details worked out I can move on to the configuration. I always step through configuration in the following order: security, locations, schedules, classifications, thesaurus terms (keywords), lookup sets, custom properties, record types and system settings. The remainder of this post will step through each and at the end I'll have a dataset with all of these records imported.
Terminology
Within the National Archives some CM concepts are referenced differently. For instance, Security Levels and Caveats are referred to as Security Classifications and Supplemental Markings respectively; so I decided to first change the terminology option on the compliance tab of the system options to "US Common".

Security
With my terminology now aligned with NARA, I created the standard security classification rankings. I'm not going to create any supplemental markings at the moment. Since I intend to demonstrate a CM declassification process it makes sense to have a few levels available as soon as possible, even if I don't use them during my initial import.

Locations
The filter option within my spreadsheet application allows me to see that there are a handful of values I could use as a location list. Now each of these locations should have a default security profile with the "Top Secret" security classification, as each could possibly have records at that level.

I have a couple of options with regard to locations:
- Manually create each location, especially since there are less than twenty distinct originators in the spreadsheet.
- Use a spreadsheet formula/function to export a new worksheet that will then be imported via DataPort's Spreadsheet Formatter
- Save the spreadsheet off as a CSV file and then use powershell to create the locations (thereby giving me greater flexibility but also requiring some manual efforts).
I decided to go the last route because I can easily re-use what I create. I downloaded the workbook from NARA and converted it from Excel to CSV. I then wrote this powershell script to extract/create all of the unique originators:
Add-Type -Path "D:\Program Files\Hewlett Packard Enterprise\Content Manager\HP.HPTRIM.SDK.dll" $db = New-Object HP.HPTRIM.SDK.Database $db.Connect $metadataFile = "F:\Dropbox\CMRamble\JFK\nara_jfk_2017release.tsv" $owners = Get-Content -Path $metadataFile | ConvertFrom-Csv -Delimiter "`t" | select "Originator" | sort-object -Property "Originator" -Unique foreach ( $owner in $owners ) { if ( [String]::IsNullOrWhiteSpace($owner.Originator) -ne $true ) { $location = New-Object HP.HPTRIM.SDK.Location -ArgumentList $db $location.TypeOfLocation = [HP.HPTRIM.SDK.LocationType]::Organization $location.IsWithin = $true $location.SortName = $owner.Originator $location.Surname = $owner.Originator $location.SecurityString = "Top Secret" $location.Save() Write-Host "Created $($location.FullFormattedName)" } }

Output from the script
Schedules, Classifications, Thesaurus Terms
I don't really know how I'll leverage these features, yet. So for now I don't really need to do anything with them.
Lookup sets
According to my field mapping I need three lookup sets: Formerly Withheld, Agency, and Doc Type. I could manually create each of these, use Data Port, or use a powershell script. Since I have a powershell script handy that can extract unique values from a column, I elect to go the powershell route.
Here is my powershell script that creates each of these three lookup sets and adds items for each unique value:
Add-Type -Path "D:\Program Files\Hewlett Packard Enterprise\Content Manager\HP.HPTRIM.SDK.dll" $db = New-Object HP.HPTRIM.SDK.Database $db.Connect $metadataFile = "F:\Dropbox\CMRamble\JFK\nara_jfk_2017release.tsv" $metaData = Get-Content -Path $metadataFile | ConvertFrom-Csv -Delimiter "`t" $fields = @("Formerly Withheld", "Agency", "Doc Type") foreach ( $field in $fields ) { $fieldItems = $metaData | select $($field) | sort-object -Property $($field) -Unique | select $($field) $lookupSet = $null $lookupSet = New-Object HP.HPTRIM.SDK.LookupSet -ArgumentList $db, $field if ( $lookupSet -eq $null ) { $lookupSet = New-Object HP.HPTRIM.SDK.LookupSet -ArgumentList $db $lookupSet.Name = $field $lookupSet.Save() Write-Host " Created '$($field)' set" } foreach ( $item in $fieldItems ) { $itemValue = $($item.$($field)) $lookupItem = New-Object HP.HPTRIM.SDK.LookupItem -ArgumentList $db, $itemValue if ( $lookupItem.Error -ne $null ) { $lookupItem = New-Object HP.HPTRIM.SDK.LookupItem -ArgumentList $lookupSet $lookupItem.Name = $itemValue $lookupItem.Save() Write-Host " Added '$($itemValue)' item" } $lookupItem = $null } $lookupSet = $null }
Here's what the results look like in my dataset...

Custom Properties
Next I created each of the required custom properties, as defined in the mapping notes at the top of this post. I, as usual, don't like doing this manually via the client. Powershell makes it very easy!
Here's my powershell script to create a field for every column in the spreadsheet. Note that I created custom properties for some of the columns that I've mapped to stock record properties (title for instance). I decided to store the original data on the record and then populate the stock properties as needed (which will be done for title, doc date, number).
Add-Type -Path "D:\Program Files\Hewlett Packard Enterprise\Content Manager\HP.HPTRIM.SDK.dll" $db = New-Object HP.HPTRIM.SDK.Database $db.Connect $lookupFields = @("NARA Formerly Withheld", "NARA Agency", "NARA Doc Type") foreach ( $lookupField in $lookupFields ) { $field = New-Object HP.HPTRIM.SDK.FieldDefinition $db $field.Name = $lookupField $field.LookupSet = New-Object HP.HPTRIM.SDK.LookupSet $db, $lookupField $field.Save() Write-Host "Created Property for Lookup Set '$($lookupField)'" } $stringFields = @("NARA File Num", "NARA To Name", "NARA From Name", "NARA Title", "NARA Originator", "NARA Record Series", "NARA Comments", "NARA Record Num", "NARA File Name") foreach ( $stringField in $stringFields ) { $field = New-Object HP.HPTRIM.SDK.FieldDefinition $db $field.Name = $stringField $field.Format = [HP.HPTRIM.SDK.UserFieldFormats]::String $field.Length = 50 $field.Save() Write-Host "Created Property '$($stringField)' as String with length $($field.Length)" } $numberFields = @("NARA Num Pages", "NARA Pages Released") foreach ( $numberField in $numberFields ) { $field = New-Object HP.HPTRIM.SDK.FieldDefinition $db $field.Name = $numberField $field.Format = [HP.HPTRIM.SDK.UserFieldFormats]::Number $field.Save() Write-Host "Created Property '$($numberField)' as Number" } $dateFields = @("NARA Release Date", "NARA Doc Date", "NARA Review Date") foreach ( $dateField in $dateFields ) { $field = New-Object HP.HPTRIM.SDK.FieldDefinition $db $field.Name = $dateField $field.Format = [HP.HPTRIM.SDK.UserFieldFormats]::Date $field.Save() Write-Host "Created Property '$($dateField)' as Date" }
Here's the output from the script...

Record Types
My dataset was prepopulated during creation because I elected to have the standard data template loaded (this was an option on the initialize page of the new dataset creation wizard). I can update the pre-created document record type so that it can support the records I want to import. During a later post I will work with folders/containers.
As the image below shows, I tagged all of the available custom properties on the document record type.
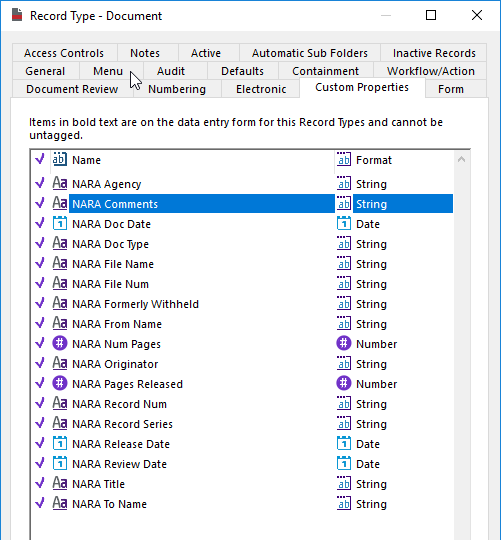
I also changed the numbering pattern to a bunch of x's. This will allow me to stuff any value into the record number field during import.

System Settings
At this point I'm ready to import the entire JFK archive. I don't need to worry about any of the system settings. I'll leave all of the default options (except terminology).
Import the Archive
In order for me to use DataPort, I would need to manipulate the data source. That's because I want to store two copies of several fields. For instance: the title. I wish to save the title column into both the record title and a custom property named "NARA Title". I could duplicate the column within the spreadsheet and then craft a DataPort project to map the two fields. I could also write a powershell script that manages these ETL (Extract, Transform, Load) tasks.
Here's the powershell script I crafted to import this spreadsheet (which was saved as a tab delimited file):
Add-Type -Path "D:\Program Files\Hewlett Packard Enterprise\Content Manager\HP.HPTRIM.SDK.dll" $db = New-Object HP.HPTRIM.SDK.Database $db.Connect $metadataFile = "F:\Dropbox\CMRamble\JFK\nara_jfk_2017release.tsv" $metaData = Get-Content -Path $metadataFile | ConvertFrom-Csv -Delimiter "`t" $doc = New-Object HP.HPTRIM.SDK.RecordType -ArgumentList $db, "Document" $fields = @("Agency", "Comments", "Doc Date", "Doc Type", "File Name", "File Num", "Formerly Withheld", "From Name", "NARA Release Date", "Num Pages", "Originator", "Record Num", "Record Series", "To Name", "Review Date", "Title") foreach ( $meta in $metaData ) { #download the record if needed $localFileName = "$PSScriptRoot\$($meta.'File Name')" if ( (Test-Path -Path $localFileName) -eq $false ) { Write-Host "Downloading $($meta.'File Name')" [Net.ServicePointManager]::SecurityProtocol = [Net.SecurityProtocolType]::Tls12 $url = "https://www.archives.gov/files/research/jfk/releases/$(($meta.'File Name').ToLower())" $wc = New-Object System.Net.WebClient $wc.DownloadFile($url, $localFileName) } #check if record already exists $record = $null $existingObject = New-Object HP.HPTRIM.SDK.TrimMainObjectSearch $db, Record $existingObject.SearchString = "number:$($meta.'Record Num')" if ( $existingObject.Count -eq 1 ) { foreach ( $rec in $existingObject ) { $record = [HP.HPTRIM.SDK.Record]($rec) break } } else { $record = New-Object HP.HPTRIM.SDK.Record -ArgumentList $db, $doc $record.LongNumber = $meta.'Record Num' $record.SetDocument($localFileName) } #correct title $record.TypedTitle = (&{If([String]::IsNullOrWhiteSpace($meta.Title)) { $meta.'File Name' } else { $meta.Title }}) #attach document if necessary if ( $record.IsElectronic -eq $false ) { $record.SetDocument($localFileName) } #populate custom properties foreach ( $field in $fields ) { if ( $field -eq "NARA Release Date" ) { $record.SetFieldValue((New-Object HP.HPTRIM.SDK.FieldDefinition -ArgumentList $db, "$($field)"), (New-Object HP.HPTRIM.SDK.UserFieldValue -ArgumentList $(($meta).$field))) } else { $record.SetFieldValue((New-Object HP.HPTRIM.SDK.FieldDefinition -ArgumentList $db, "NARA $($field)"), (New-Object HP.HPTRIM.SDK.UserFieldValue -ArgumentList $(($meta).$field))) } } $record.Save() Write-Host "Imported Record $($meta.'Record Num'): $($record.TypedTitle)" }
Sweet! I executed the script and now I've got the full NARA JFK Archive housed within an instance of Content Manager!

My next goal with this archive: setup IDOL and analyze these documents! Stay tuned.